

随着人工智能技术的飞速发展,模型研发成为了推动AI进步的核心力量,近期AI进化过程中出现了巨大的挑战——“数据墙”,数据墙指的是在AI模型研发过程中,由于数据量的大幅增长和复杂度的提升,导致模型训练难度加大、计算资源需求激增的现象,三大主流模型——深度学习模型、强化学习模型和自然语言处理模型均遭遇了这一难题,科技巨头们纷纷陷入困境,本文将深入探讨这一现象的成因、影响以及可能的解决方案。
数据墙现象的背后成因
AI进化的数据墙现象主要源于两方面原因,随着模型规模的不断扩大,对数据的数量和质量都提出了更高的要求,深度学习模型需要海量的标注数据进行训练,强化学习模型需要在庞大的环境中进行决策和策略调整,自然语言处理模型则需要大量的文本数据进行语义理解和语言生成,现实世界中的数据往往存在噪声、不平衡等问题,难以满足模型训练的需求,随着数据维度的增加和数据量的增长,计算资源的瓶颈也日益凸显,庞大的数据量使得计算资源需求激增,对计算性能的要求越来越高,现有的计算资源难以支撑大规模的模型训练。
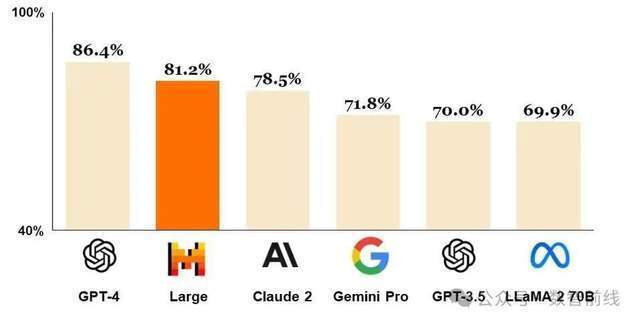
数据墙对AI研发的影响
数据墙现象给AI研发带来了极大的挑战,研发周期被拉长,由于数据量的大幅增长和计算资源的瓶颈,模型训练的时间被大大延长,研发周期被迫延长,研发成本大幅上升,庞大的数据量需要大量的计算资源进行训练和处理,计算资源的成本不断攀升,使得AI研发的成本也随之上升,模型性能难以提升,由于数据质量和计算资源的限制,模型的性能往往难以达到理想状态,限制了AI技术的应用范围。
科技巨头如何应对数据墙挑战
面对数据墙挑战,科技巨头们纷纷采取应对措施,加强数据治理,科技巨头们意识到数据质量的重要性,纷纷加强数据治理工作,通过清洗、标注等方式提高数据质量,发展分布式计算和云计算技术,为了应对计算资源瓶颈,科技巨头们大力发展分布式计算和云计算技术,提高计算性能,降低计算成本,他们还积极探索新的算法和模型结构,以应对数据墙挑战,一些公司开始尝试采用联邦学习等新型分布式机器学习算法,通过在不共享数据的情况下进行模型训练,以降低数据传输成本和隐私泄露风险,还有一些公司致力于研发更高效的硬件加速器,以提升计算性能并降低能耗。

未来展望
面对数据墙的挑战,科技巨头们正在积极寻求解决方案,未来随着技术的不断进步和算法的优化升级我们有理由相信AI进化将突破这一难题实现更加广泛的应用和发展,同时我们也应该认识到在人工智能飞速发展的同时保障数据安全、隐私保护等问题同样重要,因此未来在推动人工智能发展的同时我们也需要加强相关法规政策的制定和完善以确保技术的健康发展并造福人类社会,总之虽然当前AI进化面临着数据墙的挑战但只要我们坚定信心积极应对未来人工智能的发展前景将更加广阔,让我们共同期待人工智能的美好未来!











 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...